 Софт для бетторов на Андроиде: как выбрать для успешных прогнозов на теннис Теннис занимает значительное место в мире спортивных ставок, особенно учитывая его популярность и постоянный календарь событий, включая турниры Большого шлема: Australian Open, Roland Garros, Wimbledon и US Open (подробнее на https://betonmobile.ru/...)
Софт для бетторов на Андроиде: как выбрать для успешных прогнозов на теннис Теннис занимает значительное место в мире спортивных ставок, особенно учитывая его популярность и постоянный календарь событий, включая турниры Большого шлема: Australian Open, Roland Garros, Wimbledon и US Open (подробнее на https://betonmobile.ru/...)
 Смартфон Honor 7A DUA-L22 Версия операционной системы: Android 8.1 Oreo;
Смартфон Honor 7A DUA-L22 Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.45";
Разрешение экрана: 720x1440;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Huawei Y5 Lite DRA-LX5 Версия операционной системы: Android 8.1 Oreo;
Смартфон Huawei Y5 Lite DRA-LX5 Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.45";
Разрешение экрана: 720x1440;
Оперативная память: 1 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Honor 7A Pro AUM-L29 Версия операционной системы: Android 8.0 Oreo;
Смартфон Honor 7A Pro AUM-L29 Версия операционной системы: Android 8.0 Oreo;
Размер экрана: 5.7";
Разрешение экрана: 720x1440;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Honor 7C AUM-L41 Версия операционной системы: Android 8.0 Oreo;
Смартфон Honor 7C AUM-L41 Версия операционной системы: Android 8.0 Oreo;
Размер экрана: 5.7";
Разрешение экрана: 720x1440;
Оперативная память: 3 ГБ;
Флэш-память: 32 ГБ;
Встроенная камера: да 13 Мп + 2 Мп;
Количество SIM-карт: 2;
...
 Смартфон Samsung Galaxy J3 (2016) Gold [J320F] Версия операционной системы: Android 5.1 Lollipop;
Смартфон Samsung Galaxy J3 (2016) Gold [J320F] Версия операционной системы: Android 5.1 Lollipop;
Размер экрана: 5";
Разрешение экрана: 720x1280;
Оперативная память: 1.5 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 1;
...
 Смартфон Inoi 2 Lite Версия операционной системы: Android 7.0 Nougat;
Смартфон Inoi 2 Lite Версия операционной системы: Android 7.0 Nougat;
Размер экрана: 5";
Разрешение экрана: 480x854;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон MEIZU C9 2GB/16GB Версия операционной системы: Android 8.0 Oreo;
Смартфон MEIZU C9 2GB/16GB Версия операционной системы: Android 8.0 Oreo;
Размер экрана: 5.45";
Разрешение экрана: 720x1440;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Huawei P Smart 2019 3GB/64GB POT-LX1 Версия операционной системы: Android 9.0 Pie;
Смартфон Huawei P Smart 2019 3GB/64GB POT-LX1 Версия операционной системы: Android 9.0 Pie;
Размер экрана: 6.21";
Разрешение экрана: 1080x2340;
Оперативная память: 3 ГБ;
Флэш-память: 64 ГБ;
Встроенная камера: да 13 Мп + 2 Мп;
Количество SIM-карт: 2;
...
 Смартфон MEIZU M8 Версия операционной системы: Android 8.0 Oreo;
Смартфон MEIZU M8 Версия операционной системы: Android 8.0 Oreo;
Размер экрана: 5.7";
Разрешение экрана: 720x1440;
Оперативная память: 4 ГБ;
Флэш-память: 64 ГБ;
Встроенная камера: да 12 Мп + 5 Мп;
Количество SIM-карт: 2;
...
 Смартфон Honor 6C Pro JMM-L22 Версия операционной системы: Android 7.0 Nougat;
Смартфон Honor 6C Pro JMM-L22 Версия операционной системы: Android 7.0 Nougat;
Размер экрана: 5.2";
Разрешение экрана: 720x1280;
Оперативная память: 3 ГБ;
Флэш-память: 32 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Honor 8X 4GB/64GB JSN-L21 Версия операционной системы: Android 8.1 Oreo;
Смартфон Honor 8X 4GB/64GB JSN-L21 Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 6.5";
Разрешение экрана: 1080x2340;
Оперативная память: 4 ГБ;
Флэш-память: 64 ГБ;
Встроенная камера: да 20 Мп + 2 Мп;
Количество SIM-карт: 2;
...
 Смартфон Huawei Y6 2018 ATU-L21 Версия операционной системы: Android 8.0 Oreo;
Смартфон Huawei Y6 2018 ATU-L21 Версия операционной системы: Android 8.0 Oreo;
Размер экрана: 5.7";
Разрешение экрана: 720x1440;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Nokia 5.1 Plus Версия операционной системы: Android 8.1 Oreo;
Смартфон Nokia 5.1 Plus Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.8";
Разрешение экрана: 720x1520;
Оперативная память: 3 ГБ;
Флэш-память: 32 ГБ;
Встроенная камера: да 13 Мп + 5 Мп;
Количество SIM-карт: 2;
...
 Смартфон BQ-Mobile BQ-5520L Silk Версия операционной системы: Android 8.1 Oreo;
Смартфон BQ-Mobile BQ-5520L Silk Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.45";
Разрешение экрана: 720x1440;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Lenovo P70-A Версия операционной системы: Android 4.4 KitKat;
Смартфон Lenovo P70-A Версия операционной системы: Android 4.4 KitKat;
Размер экрана: 5";
Разрешение экрана: 720x1280;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон LeEco Le Max 2 X820 64GB Версия операционной системы: Android 6.0 Marshmallow;
Смартфон LeEco Le Max 2 X820 64GB Версия операционной системы: Android 6.0 Marshmallow;
Размер экрана: 5.7";
Разрешение экрана: 1440x2560;
Оперативная память: 4 ГБ;
Флэш-память: 64 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Ulefone S7 1GB/8GB Версия операционной системы: Android 7.0 Nougat;
Смартфон Ulefone S7 1GB/8GB Версия операционной системы: Android 7.0 Nougat;
Размер экрана: 5";
Разрешение экрана: 720x1280;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да 8 Мп + 5 Мп;
Количество SIM-карт: 2;
...
 Смартфон BQ-Mobile BQ-5300G Velvet View Версия операционной системы: Android 8.1 Oreo;
Смартфон BQ-Mobile BQ-5300G Velvet View Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.34";
Разрешение экрана: 480x960;
Оперативная память: 512 Мб;
Флэш-память: 8 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Fly Life Compact Версия операционной системы: Android 7.0 Nougat;
Смартфон Fly Life Compact Версия операционной системы: Android 7.0 Nougat;
Размер экрана: 4.95";
Разрешение экрана: 480x960;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Huawei Ascend Y5c [Y541-U02] Версия операционной системы: Android 4.4 KitKat;
Смартфон Huawei Ascend Y5c [Y541-U02] Версия операционной системы: Android 4.4 KitKat;
Размер экрана: 4.5";
Разрешение экрана: 480x854;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Nokia 3.1 Dual SIM Версия операционной системы: Android 8.0 Oreo;
Смартфон Nokia 3.1 Dual SIM Версия операционной системы: Android 8.0 Oreo;
Размер экрана: 5.2";
Разрешение экрана: 720x1440;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Motorola Moto E4 Plus [XT1771] Версия операционной системы: Android 7.0 Nougat;
Смартфон Motorola Moto E4 Plus [XT1771] Версия операционной системы: Android 7.0 Nougat;
Размер экрана: 5.5";
Разрешение экрана: 720x1280;
Оперативная память: 3 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Doogee S55 Lite Версия операционной системы: Android 8.1 Oreo;
Смартфон Doogee S55 Lite Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.5";
Разрешение экрана: 720x1440;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да 13 МП + 8 МП;
Количество SIM-карт: 2;
...
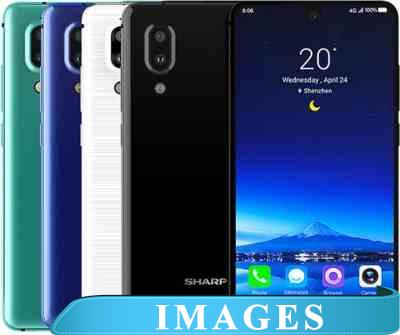 Смартфон Sharp Aquos S2 Версия операционной системы: Android 7.1 Nougat;
Смартфон Sharp Aquos S2 Версия операционной системы: Android 7.1 Nougat;
Размер экрана: 5.5";
Разрешение экрана: 1080x2040;
Оперативная память: 4 ГБ;
Флэш-память: 64 ГБ;
Встроенная камера: да двойная 12 МП + 8 МП;
Количество SIM-карт: 2;
...
 Смартфон Inoi 3 Lite Версия операционной системы: Android 7.0 Nougat;
Смартфон Inoi 3 Lite Версия операционной системы: Android 7.0 Nougat;
Размер экрана: 5";
Разрешение экрана: 480x960;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да 8 Мп + 0.3 Мп;
Количество SIM-карт: 2;
...
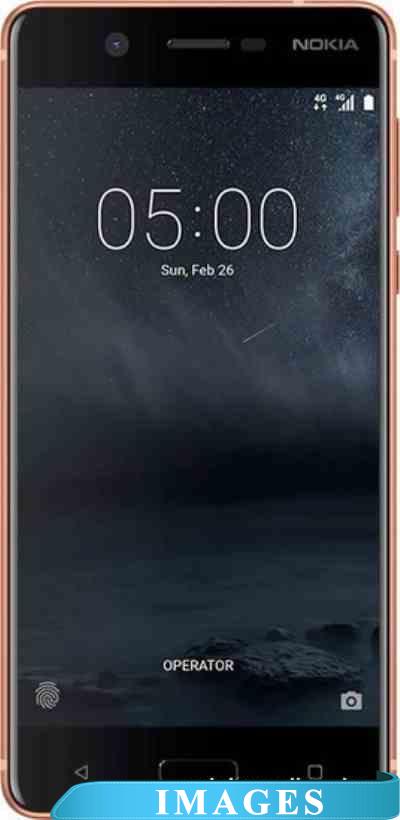 Смартфон Nokia 5 Dual SIM [TA-1053] Версия операционной системы: Android 7.1 Nougat;
Смартфон Nokia 5 Dual SIM [TA-1053] Версия операционной системы: Android 7.1 Nougat;
Размер экрана: 5.2";
Разрешение экрана: 720x1280;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
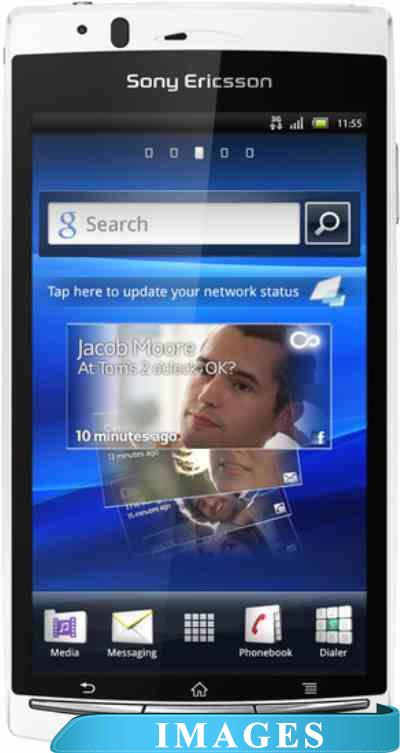 Смартфон Sony Ericsson Xperia arc S LT18i Версия операционной системы: Android 2.3 Gingerbread;
Смартфон Sony Ericsson Xperia arc S LT18i Версия операционной системы: Android 2.3 Gingerbread;
Размер экрана: 4.27";
Разрешение экрана: 480x854;
Оперативная память: 512 Мб;
Флэш-память: 320 Мб;
Встроенная камера: да 3D sweep panorama;
Количество SIM-карт: 1;
...
 Смартфон Blackview BV5800 Версия операционной системы: Android 8.1 Oreo;
Смартфон Blackview BV5800 Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.5";
Разрешение экрана: 720x1440;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да 13 Мп + 5 Мп;
Количество SIM-карт: 2;
...
 Смартфон Doogee X70 Версия операционной системы: Android 8.1 Oreo;
Смартфон Doogee X70 Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.5";
Разрешение экрана: 540x1132;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да 8 Мп + 5 Мп;
Количество SIM-карт: 2;
...
 Смартфон Nokia 2.1 Версия операционной системы: Android 8.0 Oreo;
Смартфон Nokia 2.1 Версия операционной системы: Android 8.0 Oreo;
Размер экрана: 5.5";
Разрешение экрана: 720x1280;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Huawei Nova 3i INE-LX1 4GB/128GB Версия операционной системы: Android 8.1 Oreo;
Смартфон Huawei Nova 3i INE-LX1 4GB/128GB Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 6.3";
Разрешение экрана: 1080x2340;
Оперативная память: 4 ГБ;
Флэш-память: 128 ГБ;
Встроенная камера: да 16 Мп + 2 Мп;
Количество SIM-карт: 2;
...
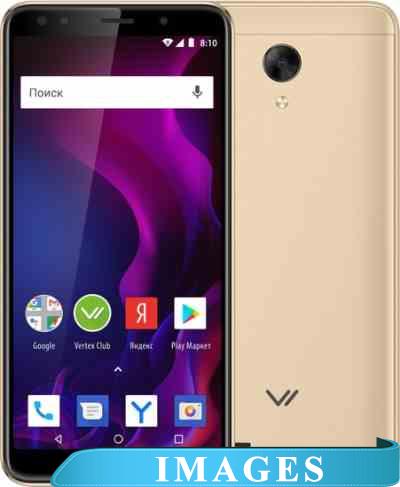 Смартфон Vertex Impress Zeon 3G Версия операционной системы: Android 8.1 Oreo;
Смартфон Vertex Impress Zeon 3G Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.5";
Разрешение экрана: 480x960;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон MEIZU M8 Lite Версия операционной системы: Android 8.0 Oreo;
Смартфон MEIZU M8 Lite Версия операционной системы: Android 8.0 Oreo;
Размер экрана: 5.7";
Разрешение экрана: 720x1440;
Оперативная память: 3 ГБ;
Флэш-память: 32 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
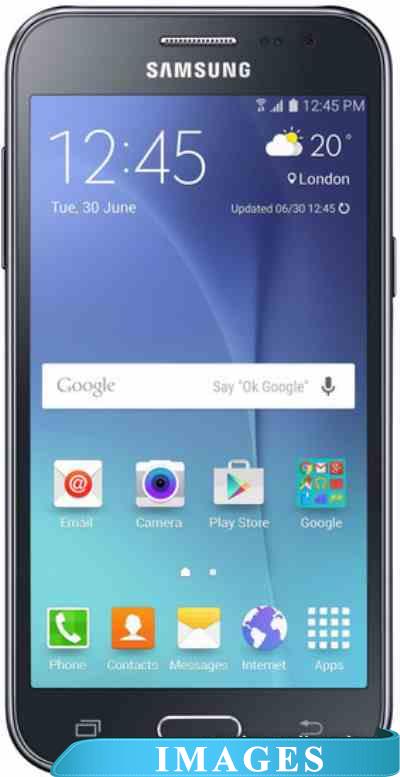 Смартфон Samsung Galaxy J2 Black [J200H/DS] Версия операционной системы: Android 5.1 Lollipop;
Смартфон Samsung Galaxy J2 Black [J200H/DS] Версия операционной системы: Android 5.1 Lollipop;
Размер экрана: 4.7";
Разрешение экрана: 540x960;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
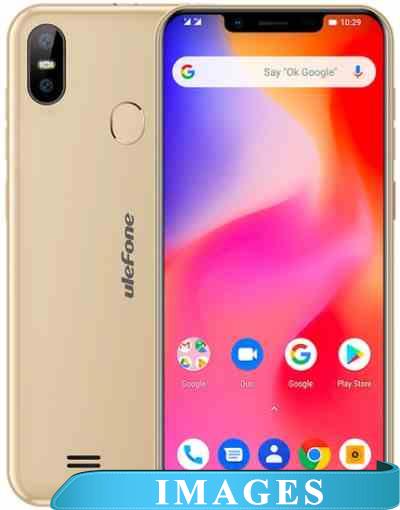 Смартфон Ulefone S10 Pro Версия операционной системы: Android 8.1 Oreo;
Смартфон Ulefone S10 Pro Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.7";
Разрешение экрана: 720x1498;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да 16 Мп + 5 Мп;
Количество SIM-карт: 2;
...
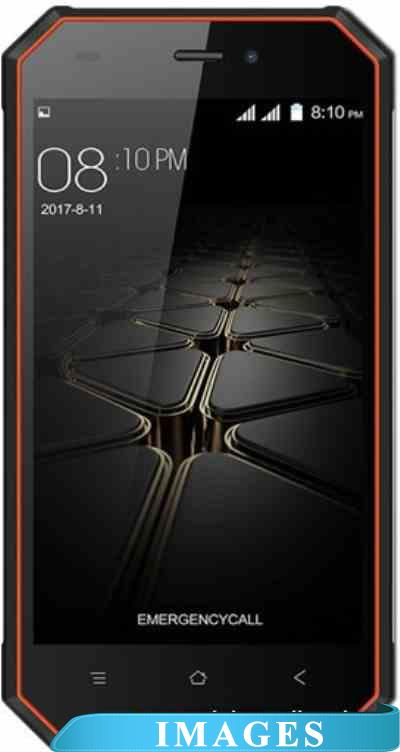 Смартфон Blackview BV4000 Pro Версия операционной системы: Android 7.0 Nougat;
Смартфон Blackview BV4000 Pro Версия операционной системы: Android 7.0 Nougat;
Размер экрана: 4.7";
Разрешение экрана: 720x1280;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
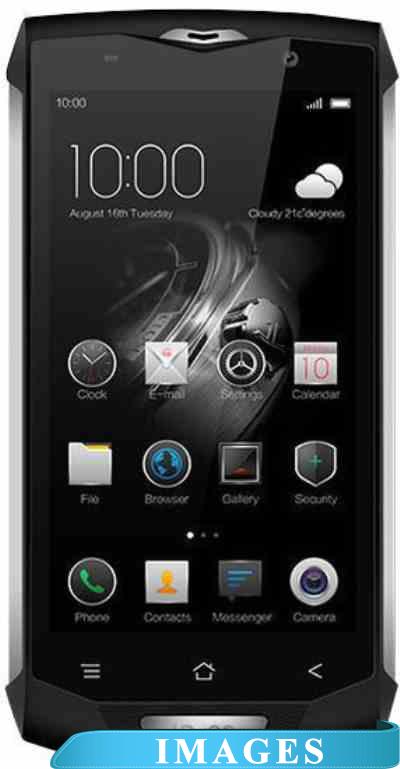 Смартфон Blackview BV8000 Pro Версия операционной системы: Android 7.0 Nougat;
Смартфон Blackview BV8000 Pro Версия операционной системы: Android 7.0 Nougat;
Размер экрана: 5";
Разрешение экрана: 1080x1920;
Оперативная память: 6 ГБ;
Флэш-память: 64 ГБ;
Встроенная камера: да Samsung S5K3P3;
Количество SIM-карт: 2;
...
 Смартфон Micromax Q357 Версия операционной системы: Android 7.0 Nougat;
Смартфон Micromax Q357 Версия операционной системы: Android 7.0 Nougat;
Размер экрана: 5";
Разрешение экрана: 480x854;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Prestigio Muze F3 Grey [PSP3532DUO] Версия операционной системы: Android 5.0 Lollipop;
Смартфон Prestigio Muze F3 Grey [PSP3532DUO] Версия операционной системы: Android 5.0 Lollipop;
Размер экрана: 5.3";
Разрешение экрана: 720x1280;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Lenovo A319 Black Версия операционной системы: Android 4.4 KitKat;
Смартфон Lenovo A319 Black Версия операционной системы: Android 4.4 KitKat;
Размер экрана: 4";
Разрешение экрана: 480x800;
Оперативная память: 512 Мб;
Флэш-память: 4 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон Oukitel C12 Pro Версия операционной системы: Android 8.1 Oreo;
Смартфон Oukitel C12 Pro Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 6.18";
Разрешение экрана: 480x996;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да 8 Мп + 2 Мп;
Количество SIM-карт: 2;
...
 Смартфон Vivo V11 Версия операционной системы: Android 8.1 Oreo;
Смартфон Vivo V11 Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 6.41";
Разрешение экрана: 1080x2340;
Оперативная память: 6 ГБ;
Флэш-память: 128 ГБ;
Встроенная камера: да 12 Мп + 5 Мп;
Количество SIM-карт: 2;
...
 Смартфон Caterpillar Cat S61 Версия операционной системы: Android 8.0 Oreo;
Смартфон Caterpillar Cat S61 Версия операционной системы: Android 8.0 Oreo;
Размер экрана: 5.2";
Разрешение экрана: 1080x1920;
Оперативная память: 4 ГБ;
Флэш-память: 64 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон TP-Link Neffos C5 Max White [TP702A] Версия операционной системы: Android 5.1 Lollipop;
Смартфон TP-Link Neffos C5 Max White [TP702A] Версия операционной системы: Android 5.1 Lollipop;
Размер экрана: 5.5";
Разрешение экрана: 1080x1920;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да ;
Количество SIM-карт: 2;
...
 Смартфон TeXet TM-5075 Версия операционной системы: Android 8.1 Oreo;
Смартфон TeXet TM-5075 Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5";
Разрешение экрана: 480x960;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да 5 Мп + 2 Мп;
Количество SIM-карт: 2;
...
 Смартфон Fly Photo Pro Версия операционной системы: Android 8.1 Oreo;
Смартфон Fly Photo Pro Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.46";
Разрешение экрана: 720x1440;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да 13 Мп + 0.3 Мп;
Количество SIM-карт: 2;
...
 Смартфон Black Fox B5 Версия операционной системы: Android 8.1 Oreo;
Смартфон Black Fox B5 Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.45";
Разрешение экрана: 480x960;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да 5 Мп + 0.3 Мп;
Количество SIM-карт: 2;
...
 Смартфон Ulefone S8 Pro Версия операционной системы: Android 7.0 Nougat;
Смартфон Ulefone S8 Pro Версия операционной системы: Android 7.0 Nougat;
Размер экрана: 5.3";
Разрешение экрана: 720x1280;
Оперативная память: 2 ГБ;
Флэш-память: 16 ГБ;
Встроенная камера: да 13 Мп + 5 Мп;
Количество SIM-карт: 2;
...
 Смартфон Oukitel WP1 Версия операционной системы: Android 8.1 Oreo;
Смартфон Oukitel WP1 Версия операционной системы: Android 8.1 Oreo;
Размер экрана: 5.5";
Разрешение экрана: 720x1440;
Оперативная память: 4 ГБ;
Флэш-память: 64 ГБ;
Встроенная камера: да 13 Мп + 2 Мп;
Количество SIM-карт: 2;
...
 Смартфон Inoi 6 Lite Версия операционной системы: Android 7.0 Nougat;
Смартфон Inoi 6 Lite Версия операционной системы: Android 7.0 Nougat;
Размер экрана: 5.5";
Разрешение экрана: 640x1280;
Оперативная память: 1 ГБ;
Флэш-память: 8 ГБ;
Встроенная камера: да 8 Мп + 0.3 Мп;
Количество SIM-карт: 2;
...
 Планшет Samsung Galaxy Tab 2 10.1 16GB 3G Titanium Silver (GT-P5100) Диагональ экрана: 10.1";
Планшет Samsung Galaxy Tab 2 10.1 16GB 3G Titanium Silver (GT-P5100) Диагональ экрана: 10.1";
Разрешение экрана: 1280x800;
Матрица экрана: PLS;
Версия операционной системы: Android 4.0 Ice Cream;
Процессор: TI OMAP4430;
Графический ускоритель: да PowerVR SGX 540;
Оперативная память: 1 ГБ;
...
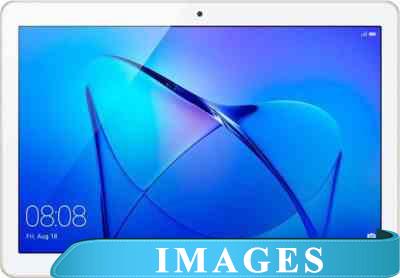 Планшет Huawei MediaPad T3 10 16GB LTE [AGS-L09] Назначение: потребительский;
Планшет Huawei MediaPad T3 10 16GB LTE [AGS-L09] Назначение: потребительский;
Диагональ экрана: 9.6";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 7.0 Nougat;
Процессор: Qualcomm MSM8917;
Графический ускоритель: да Qualcomm Adreno 308;
...
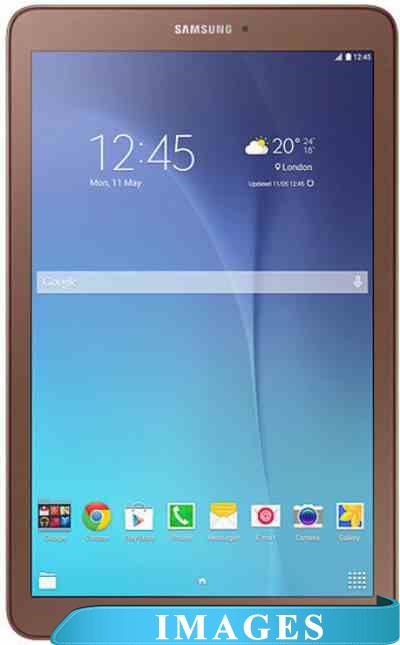 Планшет Samsung Galaxy Tab E 8GB 3G Gold Brown (SM-T561) Назначение: потребительский;
Планшет Samsung Galaxy Tab E 8GB 3G Gold Brown (SM-T561) Назначение: потребительский;
Диагональ экрана: 9.6";
Разрешение экрана: 1280x800;
Версия операционной системы: Android 4.4 KitKat;
Графический ускоритель: да ;
Оперативная память: 1.5 ГБ;
Внутренняя память: 8 ГБ;
...
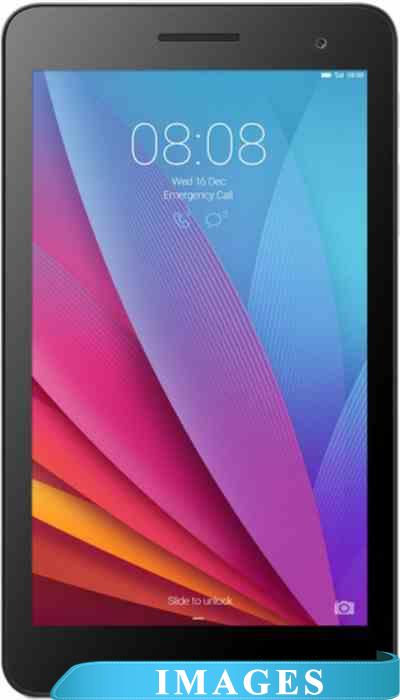 Планшет Huawei Mediapad T1 7.0 16GB 3G [T1-701u] Назначение: потребительский;
Планшет Huawei Mediapad T1 7.0 16GB 3G [T1-701u] Назначение: потребительский;
Обзоры на русскоязычных сайтах: 7.0";
Диагональ экрана: 1024x600;
Разрешение экрана: IPS;
Матрица экрана: Android;
Версия операционной системы: Spreadtrum SC7731;
Процессор: да ARM Mali-400 MP;
...
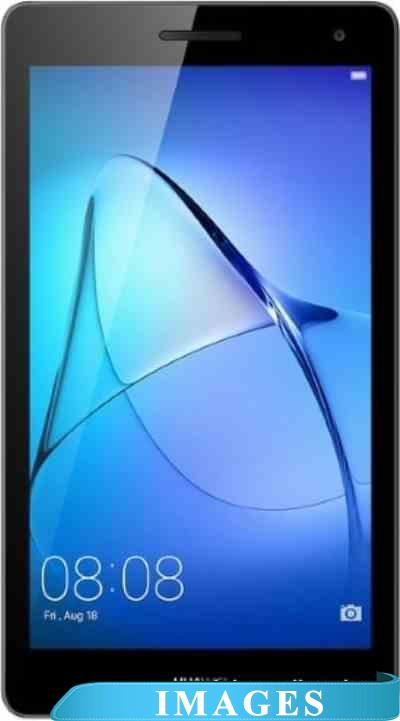 Планшет Huawei MediaPad T3 7.0 BG2-U01 8GB 3G Назначение: потребительский;
Планшет Huawei MediaPad T3 7.0 BG2-U01 8GB 3G Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1024x600;
Матрица экрана: IPS;
Версия операционной системы: Android 7.0 Nougat;
Процессор: Spreadtrum SC7731;
Графический ускоритель: да ARM Mali-400 MP;
...
 Планшет Huawei MediaPad 10 FHD 16GB Диагональ экрана: 10.1";
Планшет Huawei MediaPad 10 FHD 16GB Диагональ экрана: 10.1";
Разрешение экрана: 1920x1200;
Матрица экрана: IPS;
Версия операционной системы: Android 4.0 Ice Cream;
Процессор: Huawei HiSilicon K3V2;
Графический ускоритель: да Vivante GC4000;
Оперативная память: 1 ГБ;
...
 Планшет Huawei MediaPad T5 AGS2-L09 2GB/16GB LTE Назначение: потребительский;
Планшет Huawei MediaPad T5 AGS2-L09 2GB/16GB LTE Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1920x1080;
Матрица экрана: IPS;
Версия операционной системы: Android 8.0 Oreo;
Процессор: Huawei HiSilicon Kirin 659;
Графический ускоритель: да ARM Mali T830 MP2;
...
 Планшет ASUS MeMO Pad FHD 10 ME302C-1A005A 32GB White Назначение: потребительский;
Планшет ASUS MeMO Pad FHD 10 ME302C-1A005A 32GB White Назначение: потребительский;
Обзоры на русскоязычных сайтах: 10.1";
Диагональ экрана: 1920x1200;
Разрешение экрана: IPS;
Матрица экрана: Android;
Версия операционной системы: Intel Atom Z2560;
Процессор: да PowerVR SGX 544;
...
 Планшет Lenovo Tab 2 A7-30DC 8GB 3G Black (59444592) Назначение: потребительский;
Планшет Lenovo Tab 2 A7-30DC 8GB 3G Black (59444592) Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1024x600;
Матрица экрана: IPS;
Версия операционной системы: Android 5.0 Lollipop, Android 4.4 KitKat;
Процессор: MediaTek MT8382;
Графический ускоритель: да ARM Mali-400 MP;
...
 Планшет Prestigio Wize 3151 16GB 3G PMT3151_3G_D_CIS Назначение: потребительский;
Планшет Prestigio Wize 3151 16GB 3G PMT3151_3G_D_CIS Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 7.0 Nougat;
Процессор: MediaTek MT8321;
Графический ускоритель: да ARM Mali-400 MP;
...
 Планшет Lenovo Tab 2 A10-70L 16GB LTE Blue (ZA010015UA) Назначение: потребительский;
Планшет Lenovo Tab 2 A10-70L 16GB LTE Blue (ZA010015UA) Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1920x1200;
Матрица экрана: IPS;
Версия операционной системы: Android 5.0 Lollipop, Android 4.4 KitKat;
Процессор: MediaTek MT8732;
Графический ускоритель: да ARM Mali-T760;
...
 Планшет BQ-Mobile BQ-7083G Light 8GB 3G Назначение: потребительский;
Планшет BQ-Mobile BQ-7083G Light 8GB 3G Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1024x600;
Матрица экрана: TN+Film;
Версия операционной системы: Android 7.0 Nougat;
Процессор: Spreadtrum SC7731;
Графический ускоритель: да ;
...
 Планшет Samsung Galaxy Tab Pro 10.1 16GB LTE Black (SM-T525) Назначение: потребительский;
Планшет Samsung Galaxy Tab Pro 10.1 16GB LTE Black (SM-T525) Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 2560x1600;
Версия операционной системы: Android 4.4 KitKat;
Графический ускоритель: да Qualcomm Adreno 330;
Оперативная память: 2 ГБ;
Внутренняя память: 16 ГБ;
...
 Планшет Samsung Galaxy Note 10.1 16GB 3G Garnet Red (GT-N8000) Диагональ экрана: 10.1";
Планшет Samsung Galaxy Note 10.1 16GB 3G Garnet Red (GT-N8000) Диагональ экрана: 10.1";
Разрешение экрана: 1280x800;
Матрица экрана: PLS;
Версия операционной системы: Android 4.0 Ice Cream;
Процессор: Exynos 4412;
Графический ускоритель: да ARM Mali-400 MP;
Оперативная память: 2 ГБ;
...
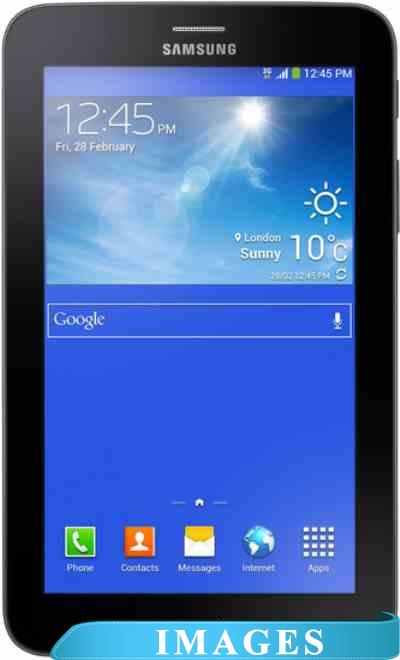 Планшет Samsung Galaxy Tab 3 Lite 8GB 3G Black (SM-T111) Назначение: потребительский;
Планшет Samsung Galaxy Tab 3 Lite 8GB 3G Black (SM-T111) Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1024x600;
Версия операционной системы: Android 4.2 Jelly Bean;
Графический ускоритель: да ;
Оперативная память: 1 ГБ;
Внутренняя память: 8 ГБ;
...
 Планшет Prestigio Wize 3131 8GB 3G [PMT3131_3G_C] Назначение: потребительский;
Планшет Prestigio Wize 3131 8GB 3G [PMT3131_3G_C] Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 6.0 Marshmallow;
Процессор: MediaTek MT8321;
Графический ускоритель: да ARM Mali-400 MP;
...
 Планшет Lenovo Yoga Tablet 10 60047 16GB 3G (59388151) Назначение: потребительский;
Планшет Lenovo Yoga Tablet 10 60047 16GB 3G (59388151) Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 4.2 Jelly Bean;
Процессор: MediaTek MT8389;
Графический ускоритель: да PowerVR SGX 544;
...
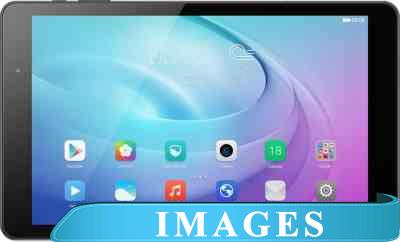 Планшет Huawei MediaPad T2 10.0 Pro 16GB LTE [FDR-A01L] Назначение: потребительский;
Планшет Huawei MediaPad T2 10.0 Pro 16GB LTE [FDR-A01L] Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1920x1200;
Матрица экрана: IPS;
Версия операционной системы: Android 5.1 Lollipop;
Процессор: Qualcomm MSM8939;
Графический ускоритель: да Qualcomm Adreno 405;
...
 Планшет Huawei MediaPad M5 lite BAH2-L09 32GB LTE Назначение: потребительский;
Планшет Huawei MediaPad M5 lite BAH2-L09 32GB LTE Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1920x1200;
Матрица экрана: IPS;
Версия операционной системы: Android 8.0 Oreo;
Процессор: Huawei HiSilicon Kirin 659;
Графический ускоритель: да ARM Mali T830 MP2;
...
 Планшет Lenovo Yoga Tablet 2-830L 16GB 4G (59428232) Назначение: потребительский;
Планшет Lenovo Yoga Tablet 2-830L 16GB 4G (59428232) Назначение: потребительский;
Диагональ экрана: 8.0";
Разрешение экрана: 1920x1200;
Матрица экрана: IPS;
Версия операционной системы: Android 4.4 KitKat;
Процессор: Intel Atom Z3745;
Графический ускоритель: да Intel HD Graphics;
...
 Планшет Digma Optima 7.21 4GB 3G Назначение: потребительский;
Планшет Digma Optima 7.21 4GB 3G Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1024x600;
Версия операционной системы: Android 4.4 KitKat;
Процессор: Spreadtrum SC5735;
Графический ускоритель: да ARM Mali-400 MP;
Оперативная память: 512 МБ;
...
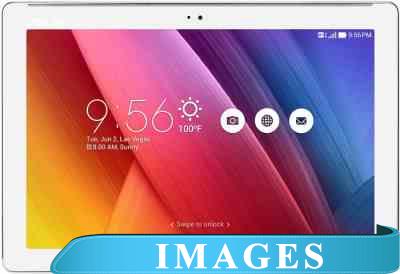 Планшет ASUS ZenPad 10 Z300CG-1B004A 16GB 3G White Назначение: потребительский;
Планшет ASUS ZenPad 10 Z300CG-1B004A 16GB 3G White Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 5.0 Lollipop;
Процессор: Intel Atom x3-C3230;
Графический ускоритель: да ARM Mali-450;
...
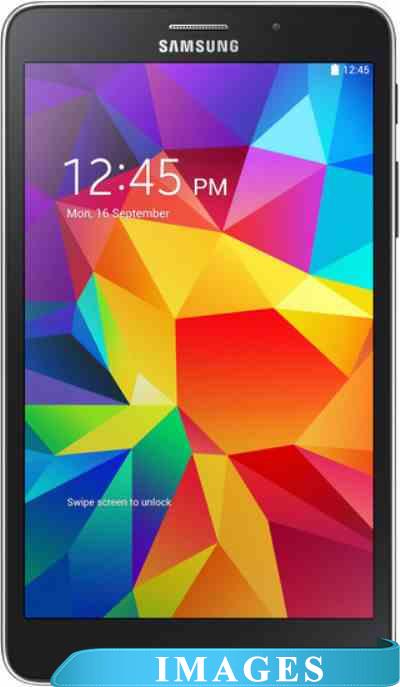 Планшет Samsung Galaxy Tab 4 7.0 8GB 3G Black (SM-T231) Назначение: потребительский;
Планшет Samsung Galaxy Tab 4 7.0 8GB 3G Black (SM-T231) Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1280x800;
Версия операционной системы: Android 4.4 KitKat;
Графический ускоритель: да ;
Оперативная память: 1.5 ГБ;
Внутренняя память: 8 ГБ;
...
 Планшет Huawei MediaPad T3 7.0 16GB BG2-W09 Назначение: потребительский;
Планшет Huawei MediaPad T3 7.0 16GB BG2-W09 Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1024x600;
Матрица экрана: IPS;
Версия операционной системы: Android 6.0 Marshmallow;
Процессор: MediaTek MT8127;
Графический ускоритель: да ARM Mali-450;
...
 Планшет Prestigio MultiPad Color 2 16GB 3G [PMT3777_3G_D_BK_CIS] Назначение: потребительский;
Планшет Prestigio MultiPad Color 2 16GB 3G [PMT3777_3G_D_BK_CIS] Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 5.1 Lollipop;
Процессор: Intel Atom x3-C3230;
Графический ускоритель: да ARM Mali-450;
...
 Планшет Lenovo Yoga Tab 3 X50F 16GB [ZA0H0030PL] Назначение: потребительский;
Планшет Lenovo Yoga Tab 3 X50F 16GB [ZA0H0030PL] Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 5.1 Lollipop;
Процессор: Qualcomm APQ8009;
Графический ускоритель: да Qualcomm Adreno 304;
...
 Планшет Tesla Neon 8.0 8GB 3G Назначение: потребительский;
Планшет Tesla Neon 8.0 8GB 3G Назначение: потребительский;
Диагональ экрана: 8.0";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 4.4 KitKat;
Процессор: MediaTek MT8382;
Графический ускоритель: да ARM Mali-400 MP;
...
 Планшет BQ-Mobile BQ-1082G Armor PRO 8GB 3G (Print 13) Назначение: потребительский;
Планшет BQ-Mobile BQ-1082G Armor PRO 8GB 3G (Print 13) Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1024x600;
Матрица экрана: TN+Film;
Версия операционной системы: Android 7.0 Nougat;
Процессор: Spreadtrum SC7731C;
Графический ускоритель: да ARM Mali-400 MP;
...
 Планшет Lenovo IdeaTab S6000 16GB (59368524) Назначение: потребительский;
Планшет Lenovo IdeaTab S6000 16GB (59368524) Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 4.2 Jelly Bean;
Процессор: MediaTek MT8125;
Графический ускоритель: да PowerVR SGX 544;
...
 Планшет Alcatel Pixi 4 7.0 8GB [8063-3BALRU1] Назначение: потребительский;
Планшет Alcatel Pixi 4 7.0 8GB [8063-3BALRU1] Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1024x600;
Матрица экрана: TN+Film;
Версия операционной системы: Android 6.0 Marshmallow;
Процессор: MediaTek MT8321;
Графический ускоритель: да ;
...
 Планшет Prestigio Grace 3101 16GB LTE PMT3101_4GH_D Назначение: потребительский;
Планшет Prestigio Grace 3101 16GB LTE PMT3101_4GH_D Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 7.0 Nougat;
Процессор: MediaTek MT8735;
Графический ускоритель: да ARM Mali-T720;
...
 Планшет TeXet TM-7854 16GB Назначение: потребительский;
Планшет TeXet TM-7854 16GB Назначение: потребительский;
Диагональ экрана: 7.85";
Разрешение экрана: 1024x768;
Матрица экрана: IPS;
Версия операционной системы: Android 4.1 Jelly Bean;
Процессор: BoxChip A31s;
Графический ускоритель: да PowerVR SGX 544;
...
 Планшет Prestigio MultiPad WIZE 3208 16GB 3G [PMT3208_3G_D_CIS] Назначение: потребительский;
Планшет Prestigio MultiPad WIZE 3208 16GB 3G [PMT3208_3G_D_CIS] Назначение: потребительский;
Диагональ экрана: 8.0";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 5.1 Lollipop;
Процессор: Intel Atom x3-C3230;
Графический ускоритель: да ARM Mali-450;
...
 Планшет eSTAR BEAUTY HD Quad Core 8GB White [MID7308W] Назначение: потребительский;
Планшет eSTAR BEAUTY HD Quad Core 8GB White [MID7308W] Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1024x600;
Версия операционной системы: Android 4.4 KitKat;
Процессор: Allwinner A33;
Графический ускоритель: да ARM Mali-400 MP;
Оперативная память: 512 МБ;
...
 Планшет TeXet TM-7026 4GB Диагональ экрана: 7.0";
Планшет TeXet TM-7026 4GB Диагональ экрана: 7.0";
Разрешение экрана: 800x480;
Матрица экрана: TN+Film;
Версия операционной системы: Android 4.0 Ice Cream;
Процессор: BoxChip A13;
Графический ускоритель: да ARM Mali-400 MP;
Оперативная память: 512 МБ;
...
 Планшет BQ-Mobile BQ-1081G Grace 8GB 3G Назначение: потребительский;
Планшет BQ-Mobile BQ-1081G Grace 8GB 3G Назначение: потребительский;
Диагональ экрана: 10.0";
Разрешение экрана: 1024x600;
Матрица экрана: TN+Film;
Версия операционной системы: Android 7.0 Nougat;
Процессор: Spreadtrum SC7731;
Графический ускоритель: да ARM Mali-400 MP;
...
 Планшет BQ-Mobile BQ-7084G Simple 8GB 3G Назначение: потребительский;
Планшет BQ-Mobile BQ-7084G Simple 8GB 3G Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1024x600;
Матрица экрана: TN+Film;
Версия операционной системы: Android 7.0 Nougat;
Процессор: Spreadtrum SC7731;
Графический ускоритель: да ARM Mali-400 MP;
...
 Планшет Philips E Line 16GB TLE821L/51 Назначение: потребительский;
Планшет Philips E Line 16GB TLE821L/51 Назначение: потребительский;
Диагональ экрана: 8.0";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 6.0 Marshmallow;
Процессор: MediaTek MT8735;
Графический ускоритель: да ARM Mali-T720;
...
 Планшет Samsung Galaxy Tab A 7.0 8GB LTE Silver [SM-T285] Назначение: потребительский;
Планшет Samsung Galaxy Tab A 7.0 8GB LTE Silver [SM-T285] Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 5.1 Lollipop;
Графический ускоритель: да ;
Оперативная память: 1.5 ГБ;
...
 Планшет Ritmix RMD-1035 8GB Диагональ экрана: 9.7";
Планшет Ritmix RMD-1035 8GB Диагональ экрана: 9.7";
Разрешение экрана: 1024x768;
Матрица экрана: IPS;
Версия операционной системы: Android 4.0 Ice Cream;
Процессор: AMLogic AML8726-MX;
Графический ускоритель: да ARM Mali-400 MP;
Оперативная память: 1 ГБ;
...
 Планшет TELEFUNKEN TF-MID9705RG 16GB 3G Назначение: потребительский;
Планшет TELEFUNKEN TF-MID9705RG 16GB 3G Назначение: потребительский;
Диагональ экрана: 9.7";
Разрешение экрана: 2048x1536;
Матрица экрана: IPS;
Версия операционной системы: Android 4.2 Jelly Bean;
Процессор: Rockchip RK3188;
Графический ускоритель: да ARM Mali-400 MP;
...
 Планшет Евросеть E-TAB 7.11 8GB Назначение: потребительский;
Планшет Евросеть E-TAB 7.11 8GB Назначение: потребительский;
Диагональ экрана: 7.0";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 5.1 Lollipop;
Процессор: Allwinner A33;
Графический ускоритель: да ARM Mali-400 MP;
...
 Планшет Lenovo Yoga Tablet 2-1050L 16GB 4G (59439314) Назначение: потребительский;
Планшет Lenovo Yoga Tablet 2-1050L 16GB 4G (59439314) Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1920x1200;
Матрица экрана: IPS;
Версия операционной системы: Android 4.4 KitKat;
Процессор: Intel Atom Z3745;
Графический ускоритель: да Intel HD Graphics;
...
 Планшет Oysters T84 8GB 3G Назначение: потребительский;
Планшет Oysters T84 8GB 3G Назначение: потребительский;
Диагональ экрана: 7.85";
Разрешение экрана: 1024x768;
Матрица экрана: IPS;
Версия операционной системы: Android 4.2 Jelly Bean;
Процессор: MediaTek MT8389;
Графический ускоритель: да PowerVR SGX 544;
...
 Планшет Huawei MediaPad T1 10 16GB LTE White (T1-A21L) Назначение: потребительский;
Планшет Huawei MediaPad T1 10 16GB LTE White (T1-A21L) Назначение: потребительский;
Обзоры на русскоязычных сайтах: 9.6";
Диагональ экрана: 1280x800;
Разрешение экрана: IPS;
Матрица экрана: Android;
Версия операционной системы: Qualcomm MSM8916;
Процессор: да Qualcomm Adreno 306;
...
 Планшет Oysters T84Ni 8GB 3G Назначение: потребительский;
Планшет Oysters T84Ni 8GB 3G Назначение: потребительский;
Диагональ экрана: 8.0";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 5.1 Lollipop;
Процессор: MediaTek MT8321;
Графический ускоритель: да ARM Mali-400 MP;
...
 Планшет Huawei MediaPad M3 8.4 64GB LTE Gold [BTV-DL09] Назначение: потребительский;
Планшет Huawei MediaPad M3 8.4 64GB LTE Gold [BTV-DL09] Назначение: потребительский;
Диагональ экрана: 8.4";
Разрешение экрана: 2560x1600;
Матрица экрана: IPS;
Версия операционной системы: Android 6.0 Marshmallow;
Процессор: Hisilicon Kirin 950;
Графический ускоритель: да ARM Mali-T880;
...
 Планшет Huawei MediaPad T3 8 16GB LTE [KOB-L09] Назначение: потребительский;
Планшет Huawei MediaPad T3 8 16GB LTE [KOB-L09] Назначение: потребительский;
Диагональ экрана: 8.0";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 7.0 Nougat;
Процессор: Qualcomm MSM8917;
Графический ускоритель: да Qualcomm Adreno 308;
...
 Планшет Prestigio Wize 3171 16GB 3G PMT3171_3G_D Назначение: потребительский;
Планшет Prestigio Wize 3171 16GB 3G PMT3171_3G_D Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 7.0 Nougat;
Процессор: MediaTek MT8321;
Графический ускоритель: да ARM Mali-400 MP;
...
 Планшет BQ-Mobile BQ-1077L Armor PRO 8GB LTE (Print 3) Назначение: потребительский;
Планшет BQ-Mobile BQ-1077L Armor PRO 8GB LTE (Print 3) Назначение: потребительский;
Диагональ экрана: 10.1";
Разрешение экрана: 1280x800;
Матрица экрана: IPS;
Версия операционной системы: Android 7.0 Nougat;
Процессор: Spreadtrum SC9832;
Графический ускоритель: да ARM Mali-400 MP;
...
 Самые полезные мобильные приложения по навигации для любителей маунтинбайка Маунтинбайк - это не просто спорт, это образ жизни, который объединяет людей, страстно увлеченных покорением бездорожья на двух колесах...
Самые полезные мобильные приложения по навигации для любителей маунтинбайка Маунтинбайк - это не просто спорт, это образ жизни, который объединяет людей, страстно увлеченных покорением бездорожья на двух колесах...
 Леброн Джеймс: Рекорды, Размышления о Карьере и Наследие в НБА Леброн Джеймс превзошёл достижения Майкла Джордана и поделился мыслями о возможном завершении своей карьеры, вызвав бурю обсуждений в мире баскетбола...
Леброн Джеймс: Рекорды, Размышления о Карьере и Наследие в НБА Леброн Джеймс превзошёл достижения Майкла Джордана и поделился мыслями о возможном завершении своей карьеры, вызвав бурю обсуждений в мире баскетбола...
 Самые полезные приложения на Android для любителей NHL С помощью приложений вы сможете оставаться в курсе всех событий НХЛ, где бы вы ни находились. От прямых трансляций матчей до последних новостей и углубленной аналитики, эти приложения предоставят вам все необходимое...
Самые полезные приложения на Android для любителей NHL С помощью приложений вы сможете оставаться в курсе всех событий НХЛ, где бы вы ни находились. От прямых трансляций матчей до последних новостей и углубленной аналитики, эти приложения предоставят вам все необходимое...
 Оптимизация приложений на Android Скорость работы приложений на Android является важным фактором, влияющим на пользовательский опыт. Разработчики приложений могут оптимизировать скорость работы своих приложений...
Оптимизация приложений на Android Скорость работы приложений на Android является важным фактором, влияющим на пользовательский опыт. Разработчики приложений могут оптимизировать скорость работы своих приложений...
 Обзор приложения Betcity для Android Приложение Betcity позволяет любителям спортивных ставок заключать пари со смартфона. Расскажем об основных особенностях софта...
Обзор приложения Betcity для Android Приложение Betcity позволяет любителям спортивных ставок заключать пари со смартфона. Расскажем об основных особенностях софта...
 Факторы, влияющие на скорость работы приложений на Android Скорость работы приложений на Android является одним из важнейших факторов, определяющих пользовательский опыт. Медленные и зависшие приложения могут вызвать разочарование...
Факторы, влияющие на скорость работы приложений на Android Скорость работы приложений на Android является одним из важнейших факторов, определяющих пользовательский опыт. Медленные и зависшие приложения могут вызвать разочарование...
 Значение дополнительных функций камеры у современных смартфонов При выборе смартфона камера является одним из наиболее важных факторов, которые следует учитывать. Конечно, все хотят высокое разрешение...
Значение дополнительных функций камеры у современных смартфонов При выборе смартфона камера является одним из наиболее важных факторов, которые следует учитывать. Конечно, все хотят высокое разрешение...
 Самые полезные приложения для любителей операционной системы Android Для операционной системы Android доступно множество полезных приложений, которые могут повысить вашу производительность, развлечь вас и облегчить вашу жизнь...
Самые полезные приложения для любителей операционной системы Android Для операционной системы Android доступно множество полезных приложений, которые могут повысить вашу производительность, развлечь вас и облегчить вашу жизнь...
 Пользователям Android предлагают спрогнозировать, кто выиграет чемпионат Англии по футболу в 2024 году Предстоящий сезон Английской Премьер-лиги (АПЛ) обещает стать одним из самых захватывающих и непредсказуемых за последние годы. В центре внимания пользователей Андроид...
Пользователям Android предлагают спрогнозировать, кто выиграет чемпионат Англии по футболу в 2024 году Предстоящий сезон Английской Премьер-лиги (АПЛ) обещает стать одним из самых захватывающих и непредсказуемых за последние годы. В центре внимания пользователей Андроид...
 Realme 12 – Новый уровень мобильной фотографии УКомпания Realme представила новый смартфон Realme 12, оснащенный передовым чипом Dimensity 6100+ и 108-Мп камерой. Компания Realme расширила свою линейку смартфонов, представив новую модель – Realme 12...
Realme 12 – Новый уровень мобильной фотографии УКомпания Realme представила новый смартфон Realme 12, оснащенный передовым чипом Dimensity 6100+ и 108-Мп камерой. Компания Realme расширила свою линейку смартфонов, представив новую модель – Realme 12...
 Как выбрать лучшее приложение для ставок на киберспорт для Android У многих БК есть собственные мобильные приложения для ставок на киберспорт. Чтобы выбрать лучший софт, стоит учитывать некоторые параметры. О них мы расскажем в этой статье...
Как выбрать лучшее приложение для ставок на киберспорт для Android У многих БК есть собственные мобильные приложения для ставок на киберспорт. Чтобы выбрать лучший софт, стоит учитывать некоторые параметры. О них мы расскажем в этой статье...
 Почему не работает приложение Winline на Android и как устранить проблемы Приложение Winline обычно работает достаточно стабильно. Однако некоторые пользователи жалуются на проблемы с работой софта на Android...
Почему не работает приложение Winline на Android и как устранить проблемы Приложение Winline обычно работает достаточно стабильно. Однако некоторые пользователи жалуются на проблемы с работой софта на Android...
 Зачем беттору скачивать приложение Winline на Android Если вы любите беттинг, приложение Winline на смартфоне существенно облегчит вашу жизнь. Расскажем о преимуществах программы и минимальных системных требованиях...
Зачем беттору скачивать приложение Winline на Android Если вы любите беттинг, приложение Winline на смартфоне существенно облегчит вашу жизнь. Расскажем о преимуществах программы и минимальных системных требованиях...
 Где скачать на Android мобильное приложение Winline Мобильное приложение позволяет любителям ставок заключать пари на матчи в любом удобном месте и в любое время при наличии интернета. Однако с загрузкой софта могут быть проблемы...
Где скачать на Android мобильное приложение Winline Мобильное приложение позволяет любителям ставок заключать пари на матчи в любом удобном месте и в любое время при наличии интернета. Однако с загрузкой софта могут быть проблемы...
 Кирилл Капризов впервые отметился шестью очками за один матч НХЛ Кирилл Капризов продолжает писать историю в Национальной хоккейной лиге. В матче регулярного чемпионата против «Ванкувер Кэнакс» российский нападающий «Миннесота Уайлд» набрал шесть очков...
Кирилл Капризов впервые отметился шестью очками за один матч НХЛ Кирилл Капризов продолжает писать историю в Национальной хоккейной лиге. В матче регулярного чемпионата против «Ванкувер Кэнакс» российский нападающий «Миннесота Уайлд» набрал шесть очков...
 Как работают приложения БК на андроид? Меньше контор, которые не предлагают возможность беттерам делать ставки со своих смартфонов. Даже оффшорные компании разрабатывают приложения для Android и iOS, обеспечивая легкий доступ к сайту...
Как работают приложения БК на андроид? Меньше контор, которые не предлагают возможность беттерам делать ставки со своих смартфонов. Даже оффшорные компании разрабатывают приложения для Android и iOS, обеспечивая легкий доступ к сайту...
 Ковальчук вошел в историю хоккея, набрав 400 очков в КХЛ и НХЛ Нападающий «Спартака» Илья Ковальчук стал вторым хоккеистом в истории, который набрал 400 и более очков в Континентальной хоккейной лиге и Национальной хоккейной лиге...
Ковальчук вошел в историю хоккея, набрав 400 очков в КХЛ и НХЛ Нападающий «Спартака» Илья Ковальчук стал вторым хоккеистом в истории, который набрал 400 и более очков в Континентальной хоккейной лиге и Национальной хоккейной лиге...
 Пользователям Android предложили поставить на трансфер Холланда в «Реал» Мадридский «Реал» отказался претендовать на норвежского нападающего "Манчестер Сити" Эрлинга Холанда Как сообщает французское издание MadeinFoot, ссылаясь на информацию от испанского журналиста Хосепа Педрероля, мадридцы вновь нацелелись на 25-летнего форварда "ПСЖ" Килиана Мбаппе...
Пользователям Android предложили поставить на трансфер Холланда в «Реал» Мадридский «Реал» отказался претендовать на норвежского нападающего "Манчестер Сити" Эрлинга Холанда Как сообщает французское издание MadeinFoot, ссылаясь на информацию от испанского журналиста Хосепа Педрероля, мадридцы вновь нацелелись на 25-летнего форварда "ПСЖ" Килиана Мбаппе...
 Топ-4 приложения для успешных ставок на AndroidПри анализе ставок на спорт учитывается множество факторов, но есть те, которые бывает сложно учесть полностью. Например, травмы спортсменов, условия судейства или даже погодные изменения. Это делает невозможным для сервисов предоставить полную гарантию точности в прогнозах...
Топ-4 приложения для успешных ставок на AndroidПри анализе ставок на спорт учитывается множество факторов, но есть те, которые бывает сложно учесть полностью. Например, травмы спортсменов, условия судейства или даже погодные изменения. Это делает невозможным для сервисов предоставить полную гарантию точности в прогнозах...
 Пользователям Android предлагают спрогнозировать победителя Лиги чемпионов-2023Эксперты букмекерских контор каждую неделю обновляют прогнозы на победителя главного турнира Европы. Каждый букмекер предлагает свою маржу и свои условия...
Пользователям Android предлагают спрогнозировать победителя Лиги чемпионов-2023Эксперты букмекерских контор каждую неделю обновляют прогнозы на победителя главного турнира Европы. Каждый букмекер предлагает свою маржу и свои условия...
 В беттинг-приложениях для Android обновлены котировки на победителя Лиги чемпионовВ главном футбольном клубном турнире Европы – Лиге чемпионов, приближается развязка на групповом этапе...
В беттинг-приложениях для Android обновлены котировки на победителя Лиги чемпионовВ главном футбольном клубном турнире Европы – Лиге чемпионов, приближается развязка на групповом этапе...
 Киберспорт на телефоне: по каким играм проводятся турниры Киберспортивные турниры проводятся не только по компьютерным играм, но и по мобильным. Желающие могут участвовать в квалификациях...
Киберспорт на телефоне: по каким играм проводятся турниры Киберспортивные турниры проводятся не только по компьютерным играм, но и по мобильным. Желающие могут участвовать в квалификациях...
 В приложении для Android можно предсказать нового обладателя «Золотого мяча» Не успели футбольные болельщики со всего мира обсудить завоевание аргентинской звездой Лионелем Месси своего очередного «Золотого мяча»...
В приложении для Android можно предсказать нового обладателя «Золотого мяча» Не успели футбольные болельщики со всего мира обсудить завоевание аргентинской звездой Лионелем Месси своего очередного «Золотого мяча»...
 Лучшие видеоигры для любителей легкой атлетики Легкая атлетика - это один из самых популярных видов спорта в мире, и многие люди мечтают о том, чтобы ощутить радость и волнение соревнований в легкой атлетике. Множество людей занимаются легкой атлетикой...
Лучшие видеоигры для любителей легкой атлетики Легкая атлетика - это один из самых популярных видов спорта в мире, и многие люди мечтают о том, чтобы ощутить радость и волнение соревнований в легкой атлетике. Множество людей занимаются легкой атлетикой...
 Лучшие android приложения для любителей тяжелой атлетики Тяжелая атлетика - это спортивная дисциплина, которая требует от спортсменов максимальных усилий, выносливости и упорства. Для поддержки и мониторинга своих тренировок и успехов существует множество приложений...
Лучшие android приложения для любителей тяжелой атлетики Тяжелая атлетика - это спортивная дисциплина, которая требует от спортсменов максимальных усилий, выносливости и упорства. Для поддержки и мониторинга своих тренировок и успехов существует множество приложений...
 Почему штанга считается основным инвентарем в силовом тренинге Штанга - это один из самых важных и фундаментальных инвентарей в силовом тренинге. Она является неотъемлемой частью оборудования в большинстве спортивных залов...
Почему штанга считается основным инвентарем в силовом тренинге Штанга - это один из самых важных и фундаментальных инвентарей в силовом тренинге. Она является неотъемлемой частью оборудования в большинстве спортивных залов...
 Сплошное разочарование? У Андре Онана пока мало что получается в составе «Манчестер Юнайтед» Футбол - это командный вид спорта, где каждый игрок имеет свою важную роль в достижении успеха команды. Однако одной из наиболее непонятных и зачастую недооцененных позиций...
Сплошное разочарование? У Андре Онана пока мало что получается в составе «Манчестер Юнайтед» Футбол - это командный вид спорта, где каждый игрок имеет свою важную роль в достижении успеха команды. Однако одной из наиболее непонятных и зачастую недооцененных позиций...
 Как выбрать планшет по основным характеристикам Планшеты стали неотъемлемой частью нашей повседневной жизни, предоставляя удобный доступ к информации, развлечениям и работе в движении. При выборе планшета...
Как выбрать планшет по основным характеристикам Планшеты стали неотъемлемой частью нашей повседневной жизни, предоставляя удобный доступ к информации, развлечениям и работе в движении. При выборе планшета...
 Лучшие приложения для любителей альпинизма Альпинизм - это увлекательное и захватывающее хобби, которое объединяет физическую активность и приключения. С современными технологиями смартфонов...
Лучшие приложения для любителей альпинизма Альпинизм - это увлекательное и захватывающее хобби, которое объединяет физическую активность и приключения. С современными технологиями смартфонов...
 Как выбрать приложение для тренировок дома: 5 советов начинающим спортсменам Всё больше людей, старающихся следить за собственной формой, занимаются спортом самостоятельно. Вместо посещения зала и работы с персональным тренером...
Как выбрать приложение для тренировок дома: 5 советов начинающим спортсменам Всё больше людей, старающихся следить за собственной формой, занимаются спортом самостоятельно. Вместо посещения зала и работы с персональным тренером...
 Три самых полезных функции беттинг-приложений для Android Многие пользователи смартфонов на базе процессоров Android устанавливают себе приложения букмекерских контор...
Три самых полезных функции беттинг-приложений для Android Многие пользователи смартфонов на базе процессоров Android устанавливают себе приложения букмекерских контор...
 3 лучших приложения для езды на велосипеде Велосипедные приложения будут кстати в любой поездке — будь то путь на работу или запланированная тренировка выходного дня...
3 лучших приложения для езды на велосипеде Велосипедные приложения будут кстати в любой поездке — будь то путь на работу или запланированная тренировка выходного дня...
 Пользователям Android предлагают предсказать победителя Лиги чемпионов Азии НФутбольные болельщики в новом сезоне с особым вниманием следят не только за матчами европейской Лиги чемпионов, но и за аналогичным турниром в Азии...
Пользователям Android предлагают предсказать победителя Лиги чемпионов Азии НФутбольные болельщики в новом сезоне с особым вниманием следят не только за матчами европейской Лиги чемпионов, но и за аналогичным турниром в Азии...
 Пользователи Android могут спрогнозировать имя лучшего бомбардира Лиги чемпионов В главном футбольном турнире Европы – Лиге чемпионов, стартовал новый сезон, а пользователи Android имеют шанс предсказать его лучшего бомбардира...
Пользователи Android могут спрогнозировать имя лучшего бомбардира Лиги чемпионов В главном футбольном турнире Европы – Лиге чемпионов, стартовал новый сезон, а пользователи Android имеют шанс предсказать его лучшего бомбардира...
 Пользователи Android могут предсказать победителя Евро-2024 Несмотря на то, что квалификационный турнир на футбольный чемпионат Европы еще в самом разгаре, представители беттинг-сферы уже сейчас предлагают назвать имя будущего триумфатора Евро-2024...
Пользователи Android могут предсказать победителя Евро-2024 Несмотря на то, что квалификационный турнир на футбольный чемпионат Европы еще в самом разгаре, представители беттинг-сферы уже сейчас предлагают назвать имя будущего триумфатора Евро-2024...
 «Зенит» сохраняет статус главного фаворита Премьер-лиги В Российской футбольной Премьер-лиге пройдена уже почти четверть турнирной дистанции нового сезона...
«Зенит» сохраняет статус главного фаворита Премьер-лиги В Российской футбольной Премьер-лиге пройдена уже почти четверть турнирной дистанции нового сезона...
 Проект Legalbet: сайт о ставках на спорт, где каждый найдёт полезную информацию Компания «Легалбет» — международные СМИ, которые честно рассказывают о букмекерских конторах (БК) и ставках на спорт (беттинге). На сайте проекта собрано всё необходимое для тех, кто уже заключает пари или только разбирается в теме ставок: от спортивных новостей до акций букмекеров...
Проект Legalbet: сайт о ставках на спорт, где каждый найдёт полезную информацию Компания «Легалбет» — международные СМИ, которые честно рассказывают о букмекерских конторах (БК) и ставках на спорт (беттинге). На сайте проекта собрано всё необходимое для тех, кто уже заключает пари или только разбирается в теме ставок: от спортивных новостей до акций букмекеров...
 Котировки на обладателя «Золотого мяча» для пользователей Android Пользователи смартфонов на базе Android могут сделать прогноз на будущего обладателя главного индивидуального приза в мире футбола – «Золотого мяча»...
Котировки на обладателя «Золотого мяча» для пользователей Android Пользователи смартфонов на базе Android могут сделать прогноз на будущего обладателя главного индивидуального приза в мире футбола – «Золотого мяча»...
 Пользователи Android могут сделать прогноз на последний большой теннисный турнир года Не за горами старт последнего теннисного турнира серии Большого шлема в 2023-м году – Открытого чемпионата США, и уже сейчас пользователи смартфонов на базе Android имеют шанс сделать свои прогнозы на итоги этого соревнования...
Пользователи Android могут сделать прогноз на последний большой теннисный турнир года Не за горами старт последнего теннисного турнира серии Большого шлема в 2023-м году – Открытого чемпионата США, и уже сейчас пользователи смартфонов на базе Android имеют шанс сделать свои прогнозы на итоги этого соревнования...
 Котировки на матч за Суперкубок Европы для пользователей Android Футбольные болельщики, использующие смартфоны на базе процессоров Android, могут сделать свои прогнозы на матч за первый футбольный трофей нового сезона в Европе – Суперкубок УЕФА...
Котировки на матч за Суперкубок Европы для пользователей Android Футбольные болельщики, использующие смартфоны на базе процессоров Android, могут сделать свои прогнозы на матч за первый футбольный трофей нового сезона в Европе – Суперкубок УЕФА...
 Топ-3 турнира для ставок с Андроида этим летом Любители спорта уже пережили немало захватывающих эмоций летом-2023 года, наблюдая за соревнованиями высочайшего уровня, однако оставшиеся полтора жарких месяца готовят новые сражения звездных спортсменов...
Топ-3 турнира для ставок с Андроида этим летом Любители спорта уже пережили немало захватывающих эмоций летом-2023 года, наблюдая за соревнованиями высочайшего уровня, однако оставшиеся полтора жарких месяца готовят новые сражения звездных спортсменов...
 Назван главный фаворит нового розыгрыша Лиги чемпионов Английский «Манчестер Сити», победивший итальянский «Интер» в финальном матче в Стамбуле, стал новым обладателем главного трофея Лиги чемпионов. И этой же команде прочат успех уже в следующем сезоне эксперты беттинг-сферы...
Назван главный фаворит нового розыгрыша Лиги чемпионов Английский «Манчестер Сити», победивший итальянский «Интер» в финальном матче в Стамбуле, стал новым обладателем главного трофея Лиги чемпионов. И этой же команде прочат успех уже в следующем сезоне эксперты беттинг-сферы...
 Как поставить на финал Лиги чемпионов с Андроида Уже скоро состоится главное футбольное событие сезона в Европе – финал самого престижного клубного соревнования континента, Лиги чемпионов. В решающем поединке Лиги чемпионов сезона 2022/23 годов схлестнутся английский «Манчестер Юнайтед»...
Как поставить на финал Лиги чемпионов с Андроида Уже скоро состоится главное футбольное событие сезона в Европе – финал самого престижного клубного соревнования континента, Лиги чемпионов. В решающем поединке Лиги чемпионов сезона 2022/23 годов схлестнутся английский «Манчестер Юнайтед»...
 3 лучших теннисных приложений для Android Теннис как вид спорта зародился еще два века назад в Англии, но до сих пор пользуется огромной популярностью среди игроков всех возрастов. Для поклонников это игры созданы приложения, благодаря которым можно всегда оставаться в курсе самых актуальных событий ...
3 лучших теннисных приложений для Android Теннис как вид спорта зародился еще два века назад в Англии, но до сих пор пользуется огромной популярностью среди игроков всех возрастов. Для поклонников это игры созданы приложения, благодаря которым можно всегда оставаться в курсе самых актуальных событий ...
 Лучшие приложения и игры НХЛ для Android Национальная Хоккейная Лига – самый популярный чемпионат во всем мире, в котором выступают лучшие хоккеисты планеты. Поклонники «Большого шоу» регулярно интересуются результатами матчей, статистикой и актуальными новостями любимых команд...
Лучшие приложения и игры НХЛ для Android Национальная Хоккейная Лига – самый популярный чемпионат во всем мире, в котором выступают лучшие хоккеисты планеты. Поклонники «Большого шоу» регулярно интересуются результатами матчей, статистикой и актуальными новостями любимых команд...
 Топ-3 баскетбольных приложений для Android Век новых технологий и бурно развивающаяся индустрия мобильных приложений не обошли стороной один из самых популярных видов спорта – баскетбол. Любители игры с оранжевым мячом могут следить за результатами матчей любимых команд...
Топ-3 баскетбольных приложений для Android Век новых технологий и бурно развивающаяся индустрия мобильных приложений не обошли стороной один из самых популярных видов спорта – баскетбол. Любители игры с оранжевым мячом могут следить за результатами матчей любимых команд...
 Лучшие киберспортивные приложения для Android Киберспорт в последние годы стал массовым явлением. События виртуального спорта привлекают внимание наравне с реальными турнирами, поэтому каждый день создаются новые сервисы для просмотра матчей и общения с аудиторией ...
Лучшие киберспортивные приложения для Android Киберспорт в последние годы стал массовым явлением. События виртуального спорта привлекают внимание наравне с реальными турнирами, поэтому каждый день создаются новые сервисы для просмотра матчей и общения с аудиторией ...
 Лучшие приложения для трансляций футбольных матчей на Android Yacine TV – лучшее приложение для просмотра прямых трансляций футбольных матчей на Android в 2023 году. Одной из главных причин его популярности является то, что оно предлагает своим клиентам возможность смотреть матчи в различных форматах видео, включая 720p, 360p и 244p ...
Лучшие приложения для трансляций футбольных матчей на Android Yacine TV – лучшее приложение для просмотра прямых трансляций футбольных матчей на Android в 2023 году. Одной из главных причин его популярности является то, что оно предлагает своим клиентам возможность смотреть матчи в различных форматах видео, включая 720p, 360p и 244p ...
 Как выбрать гемблинг-ресурс для игры в слоты Выбор игрового клуба для новичков сложен, так как они не знают, по каким критериям его оценивать. В выборе могут помочь готовые топы — например, рейтинг казино от сайта Ставочка. Если все-таки есть желание подобрать игорное заведение самостоятельно, вот на что стоит обратить внимание...
Как выбрать гемблинг-ресурс для игры в слоты Выбор игрового клуба для новичков сложен, так как они не знают, по каким критериям его оценивать. В выборе могут помочь готовые топы — например, рейтинг казино от сайта Ставочка. Если все-таки есть желание подобрать игорное заведение самостоятельно, вот на что стоит обратить внимание...
 Как начать сотрудничество с 1xBet - партнерская программа букмекерской конторы bet winner Навыки привлечения трафика могут стать отличным способом для заработка в интернете. В таких услугах заинтересованы крупные компании, которым требуются рекламные партнеры. Среди них 1xbetaffiliates.net/ru/ - партнерская программа букмекерской конторы bet winner, подробнее: 1xbetaffiliates.net...
Как начать сотрудничество с 1xBet - партнерская программа букмекерской конторы bet winner Навыки привлечения трафика могут стать отличным способом для заработка в интернете. В таких услугах заинтересованы крупные компании, которым требуются рекламные партнеры. Среди них 1xbetaffiliates.net/ru/ - партнерская программа букмекерской конторы bet winner, подробнее: 1xbetaffiliates.net...
 Невероятная победа ПСВ в Лиге Чемпионов 1987-89 Нидерландский футбольный клуб ПСВ стабильно удерживает звание одного из лучших в стране. В его активе десятки Кубков и Суперкубков Нидерландов, а также 24 победы в национальном чемпионате. На европейских и мировых турнирах результаты “красно-белых” значительно скромнее...
Невероятная победа ПСВ в Лиге Чемпионов 1987-89 Нидерландский футбольный клуб ПСВ стабильно удерживает звание одного из лучших в стране. В его активе десятки Кубков и Суперкубков Нидерландов, а также 24 победы в национальном чемпионате. На европейских и мировых турнирах результаты “красно-белых” значительно скромнее...
 Как Неаполь выступал в Лиге Чемпионов 2016/2017 Клуб «Наполи» считается одной из самых популярных футбольных команд Италии. И это при том, что у нее, относительно, скромные достижения. Так, лишь в 1987 и 1990 годах ей удавалось стать чемпионом Серии А, также было шесть Кубков Италии. Кстати, на все будущие достижения неаполитанцев можно делать безопасные ставки на спорт...
Как Неаполь выступал в Лиге Чемпионов 2016/2017 Клуб «Наполи» считается одной из самых популярных футбольных команд Италии. И это при том, что у нее, относительно, скромные достижения. Так, лишь в 1987 и 1990 годах ей удавалось стать чемпионом Серии А, также было шесть Кубков Италии. Кстати, на все будущие достижения неаполитанцев можно делать безопасные ставки на спорт...
 Упорная борьба в Группе С Лиги чемпионов 2017/2018 Группа С в Лиге чемпионов сезона 2017/2018 подарила любителям футбола массу ярких впечатлений. В ней вели упорную борьбу сразу три команды, которые были сопоставимы по своей силе, что давало место интриге. Кстати, на любой матч ЛЧ вы можете сделать выгодную ставку...
Упорная борьба в Группе С Лиги чемпионов 2017/2018 Группа С в Лиге чемпионов сезона 2017/2018 подарила любителям футбола массу ярких впечатлений. В ней вели упорную борьбу сразу три команды, которые были сопоставимы по своей силе, что давало место интриге. Кстати, на любой матч ЛЧ вы можете сделать выгодную ставку...
 Игры на деньги, казино Беларуси для Android Недавно вышедшая статья эксперта сайта Casino Zeus Алексея Иванова посвящена новым казино Беларуси. Какие игровые площадки доступны на белорусские деньги, какими приветственными бонусами они встречают новичков, как игроку разобраться — положительная репутация у игорного заведения или нет...
Игры на деньги, казино Беларуси для Android Недавно вышедшая статья эксперта сайта Casino Zeus Алексея Иванова посвящена новым казино Беларуси. Какие игровые площадки доступны на белорусские деньги, какими приветственными бонусами они встречают новичков, как игроку разобраться — положительная репутация у игорного заведения или нет...
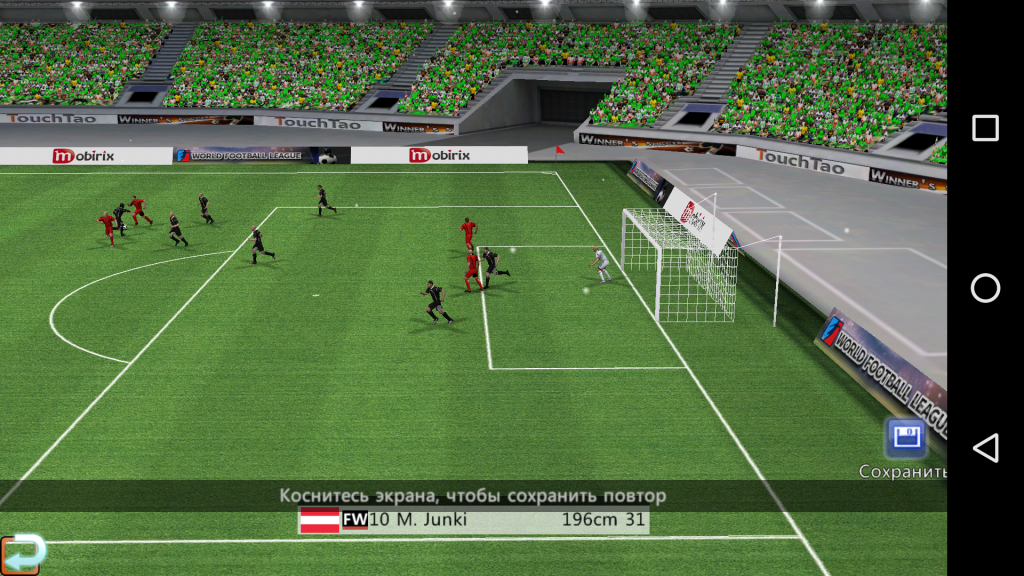 Топ-4 футбольных симуляторов для Android Футбол является самым популярным видом спорта на планете. В нём сотни лиг, тысячи профессиональных команды и десятки тысяч спортсменов...
Топ-4 футбольных симуляторов для Android Футбол является самым популярным видом спорта на планете. В нём сотни лиг, тысячи профессиональных команды и десятки тысяч спортсменов...
 Лучшие беговые приложения для Android (часть 2) Продолжаем рассказывать о лучших приложениях для тех, кто хочет поддерживать себя в форме, совершая регулярные пробежки...
Лучшие беговые приложения для Android (часть 2) Продолжаем рассказывать о лучших приложениях для тех, кто хочет поддерживать себя в форме, совершая регулярные пробежки...
 Лучшие бесплатные Android-игры для фанатов хоккея Хоккей считает одним из популярнейших видов спорта, который по количеству поклонников уступает лишь футболу и баскетболу, не требующим такой сложной экипировки и специальной площадки...
Лучшие бесплатные Android-игры для фанатов хоккея Хоккей считает одним из популярнейших видов спорта, который по количеству поклонников уступает лишь футболу и баскетболу, не требующим такой сложной экипировки и специальной площадки...
 Лучшие беговые приложения для Android (часть 1) Бег является способом поддержания хорошей физической формы, похудения, источником сил и энергии, а также лекарством от бессонницы и нервного напряжения. Начать бегать и не потерять мотивацию вам помогут специальные приложения для Android...
Лучшие беговые приложения для Android (часть 1) Бег является способом поддержания хорошей физической формы, похудения, источником сил и энергии, а также лекарством от бессонницы и нервного напряжения. Начать бегать и не потерять мотивацию вам помогут специальные приложения для Android...
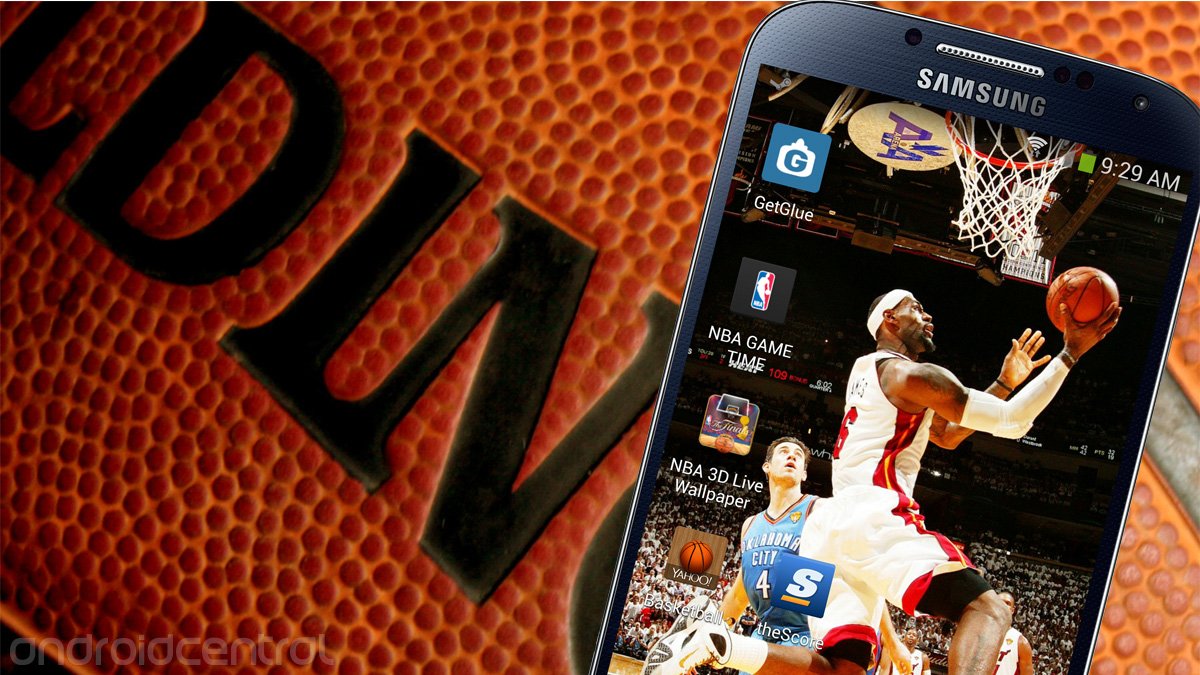 5 Android-приложений для любителей баскетбола Если вам нравится баскетбол и вы хотите всегда оставаться в курсе последних новостей и результатов, расскажем о приложениях, которые окажутся вам полезны...
5 Android-приложений для любителей баскетбола Если вам нравится баскетбол и вы хотите всегда оставаться в курсе последних новостей и результатов, расскажем о приложениях, которые окажутся вам полезны...
 Лучшие симуляторы крикета для Android Сегодня крикет имеет большую популярность по всему миру. Кто-то сам играет в него, кто-то с удовольствием смотрит матчи, а кто-то настолько увлечён этим видом спорта, что устанавливает на смартфон симуляторы крикета и пробует себя в роли игрока или менеджера команды...
Лучшие симуляторы крикета для Android Сегодня крикет имеет большую популярность по всему миру. Кто-то сам играет в него, кто-то с удовольствием смотрит матчи, а кто-то настолько увлечён этим видом спорта, что устанавливает на смартфон симуляторы крикета и пробует себя в роли игрока или менеджера команды...
 3 лучших файтинга на Android Представляем подборку файтингов, которые точно не оставят равнодушными любителей жанра. Все игры из этой статьи можно скачать в Google Play...
3 лучших файтинга на Android Представляем подборку файтингов, которые точно не оставят равнодушными любителей жанра. Все игры из этой статьи можно скачать в Google Play...
 Лучшие Android-приложения для тренировок в зале (часть 2) Продолжаем рассказывать о лучших мобильных программах для самостоятельных тренировок, которые можно загрузить в Google Play...
Лучшие Android-приложения для тренировок в зале (часть 2) Продолжаем рассказывать о лучших мобильных программах для самостоятельных тренировок, которые можно загрузить в Google Play...
 Лучшие Android-приложения для тренировок в зале (часть 1) Если вам хочется привести себя в форму, сбросить лишний вес или нарастить мышечную массу, приобретение абонемента в спортзал станет лучшим решением...
Лучшие Android-приложения для тренировок в зале (часть 1) Если вам хочется привести себя в форму, сбросить лишний вес или нарастить мышечную массу, приобретение абонемента в спортзал станет лучшим решением...
 Лучшие гонки для Android за 2022 год Согласно статистике за 2022 год, число тех, кто играет на мобильных устройствах, примерно равно количеству любителей гейминга на ПК. Поэтому нет ничего удивительного в том, что гонки, один из самых популярных жанров спортивных симуляторов, перекочевали на смартфоны...
Лучшие гонки для Android за 2022 год Согласно статистике за 2022 год, число тех, кто играет на мобильных устройствах, примерно равно количеству любителей гейминга на ПК. Поэтому нет ничего удивительного в том, что гонки, один из самых популярных жанров спортивных симуляторов, перекочевали на смартфоны...
![]() Лучшие трекеры сна для Android В наше время многие люди страдают от недосыпа, бессонницы и плохого качества сна. Но современные технологии помогут вам контролировать свой сон, чтобы эффективно отдыхать ночью. Важность качественного ночного отдыха трудно переоценить...
Лучшие трекеры сна для Android В наше время многие люди страдают от недосыпа, бессонницы и плохого качества сна. Но современные технологии помогут вам контролировать свой сон, чтобы эффективно отдыхать ночью. Важность качественного ночного отдыха трудно переоценить...
 Криштиану Роналду пользуется Android-смартфоном Криштиану Роналду, один из самых популярных спортсменов планеты, был замечен со смартфоном от компании Huawei. Португальский нападающий является пятикратным обладателем самой престижной личной награды в футболе, «Золотого мяча». Роналду принадлежит множество рекордов...
Криштиану Роналду пользуется Android-смартфоном Криштиану Роналду, один из самых популярных спортсменов планеты, был замечен со смартфоном от компании Huawei. Португальский нападающий является пятикратным обладателем самой престижной личной награды в футболе, «Золотого мяча». Роналду принадлежит множество рекордов...
 Лучшие приложения для ставок на устройства с ОС Андроид За последние 10 лет большинство клиентов букмекерских контор отдает предпочтение ставкам с телефона. Букмекеры учитывают пожелания аудитории, поэтому в 2022 году все легальные БК в России предоставляют клиентам приложения для мобильных устройств...
Лучшие приложения для ставок на устройства с ОС Андроид За последние 10 лет большинство клиентов букмекерских контор отдает предпочтение ставкам с телефона. Букмекеры учитывают пожелания аудитории, поэтому в 2022 году все легальные БК в России предоставляют клиентам приложения для мобильных устройств...